亅 僋儘僗廤寁偺傒偱偼夝庍偑擄偟偄傛偆側栤戣傪夝寛偟偨偄
亅 傛傝暋嶨側尨棟丒尰徾傪傂傕夝偒丄棟榑揑崻嫆偵婎偯偔嵟揔側棊偲偟偳偙傠傪帵嵈偟偰傎偟偄
偙偺傛偆側偲偒偵懡曄検夝愅偼桳梡側庤朄偱偡丅
嬤擭偺僷僜僐儞傗SW乮僜僼僩僂僃傾乯偺恑曕偼栚妎偟偄傕偺偱偁傝丄斾妑揑梕堈偵懡曄検夝愅傪埖偊傞傛偆偵側傝傑偟偨丅
僜僼僩僂僃傾僀儞僞乕僼僃僀僗偺巜帵偝傟傞傑傑偵僆儁儗乕僔儑儞傪巤偣偽價僕儏傾儖偺偒傟偄側僠儍乕僩側偳偑姰惉偟傑偡偑丄偦傟偼杮摉偵揔愗側寢壥側偺偱偟傚偆偐丠偁傞偄偼丄崱屻偺懳墳嶔傪揑妋偵帵嵈偟偰偄傞傕偺偲尵偊傞偺偱偟傚偆偐丅
僜僼僩僂僃傾傪娙扨偵憖嶌偱偒傞偙偲偼戝曄婌偽偟偄偙偲偱偡偑丄偦偺棟榑揑崻嫆傗杮幙傪偍傠偦偐偵偡傞偙偲偼偄偨偢傜側夝庍傪彽偒偐偹側偄婋尟側偙偲偩偲巚傢傟傑偡丅
CBR偱偼攚屻偵偁傞棟榑揑崻嫆傗杮幙偵傕徟揰傪摉偰揔愗側暘愅曽朄傪慖戰偟丄傛傝愻楙偝傟偨寢壥偺偛曬崘傪栚巜偟偰偍傝傑偡丅
椺偊偽丄傛偔偁傞働乕僗偱偡偑夝愅僜僼僩偱"場巕暘愅"傪慖戰偡傞偲僨僼僅儖僩偺場巕拪弌曽朄偼亂庡惉暘暘愅亃偱偁偭偨傝亂場巕暘愅亃偱偁偭偨傝偟傑偡丅偱偡偑丄場巕暘愅偲庡惉暘暘愅偼悢棟揑偵崜帡偟偰偄傑偡偑丄偦偺崻杮偺峫偊曽偼帡偰旕側傞傕偺偱偡丅
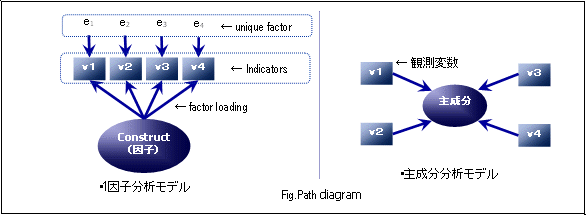
場巕暘愅偼娤應曄悢(Indicators)傪應掕偱偒側偄嫟捠偺梫場乮場巕乯偐傜愢柧偡傞儌僨儖偲場巕埲奜偺撈帺惈偐傜愢柧偝傟傞儌僨儖偱昞尰偱偒傑偡丅偙偙偱場巕偼奣擮偺廤栺傪昞偡傕偺(Constract)偲掕媊偝傟丄尨棟丒尰徾丒栤戣偺扨弮昞尰壔丄夝庍偺偨傔偺堦栶傪扴偄傑偡丅椺偊偽丄娤應曄悢乮幚嵺偵挷嵏側偳偱懳徾幰偵幙栤偡傞崁栚乯傪1)1儠寧偺偍偙偯偐偄丄2)歯岲昳偺強桳悢丄3)僄儞僎儖學悢 偲偟偨偲偒丄偙偺攚屻偵偼"惗妶悈弨偺崅偝"偲偄偆嫟捠偺娤應偱偒側偄愽嵼揑側梫場偑懚嵼偟丄偙偺崅掅偑1)-3)偺娤應曄悢偵塭嬁傪媦傏偟偰偄傞偲懆偊傞偙偲偑偱偒傑偡丅偟偐偟丄幚嵺偵偼娤應曄悢傊偺塭嬁偼偙傟偩偗偱偼側偔丄椺偊偽歯岲昳偺強桳悢側傜偽丄偁傞恖偼僽儔儞僪巙岦偑嫮偔丄偨偲偊惗妶偑嬯偟偔偲傕帺暘偑岲偒側傕偺傪懙偊偨偄偲偄偆梫場傕懚嵼偡傞偐傕偟傟傑偣傫丅偙偺傛偆偵嫟捠揑側愽嵼曄悢偩偗偱偼愢柧偱偒側偄梫場傪岆嵎曄悢乮撈帺惈:unique factor乯偲偟偰儌僨儖傪昞尰偟傑偡丅場巕暘愅偼攚屻偵偁傞嫟捠揑側梫場乮愽嵼曄悢乯偐傜偺塭嬁嬶崌乮場巕晧壸検丗Factor loading乯偵庡娽傪抲偄偨暘愅偱偡丅
堦曽丄庡惉暘暘愅偼偦偺媡偵嬤偄峫偊曽偱丄偄傠偄傠側娤應曄悢偐傜乬庡惉暘乭偲偡傞崌惉曄悢傪慄宍寢崌偵傛傝惗惉偟偰丄僨乕僞慡懱偺忬懺傪尒搉偡偙偲傪庡栚揑偲偟傑偡丅椉幰偺戝偒側堘偄偼岆嵎曄悢乮撈帺惈乯偺桳柍偲娤應曄悢偲愽嵼曄悢乮場巕乯娫偺場壥偺曽岦偱偡丅
[場巕暘愅]-[場巕拪弌曽朄丗庡惉暘暘愅]偲偼丄嫟捠惈偺弶婜抣傪侾乮撈帺惈傪0)偵愝掕偟偰庡場巕朄偱悇掕偡傞曽朄偱偡丅乮偮傑傝場巕偺夞揮傪偐偗側偗傟偽丄憡娭峴楍傪暘愅尦偲偡傞庡惉暘暘愅偺寢壥偵堦抳偟傑偡丅乯
場巕暘愅偵枩擻側曽朄偲偄偆傕偺偼懚嵼偟傑偣傫丅嫟捠惈偺弶婜愝掕乮偦偺壓尷抣偼抦傜傟偰偄傑偡乯偵偼壗傜悢棟揑崻嫆偼懚嵼偟側偄偺偱丄傕偪傠傫偙偺曽朄偱傕娫堘偄偲偼尵偊傑偣傫偑丄場巕晧壸検偑崅傔偵尒愊傜傟偰偟傑偆壜擻惈傕斲傔側偄偺偱偼側偄偱偟傚偆偐丅傑偨丄偙偺[場巕拪弌曽朄]偺拞偵偁傞偦偺懠偺僆僾僔儑儞偼偳偺傛偆側帪偵巊偊偽椙偄偺偱偟傚偆偐丒丒? 偙偺傛偆偵僜僼僩僂僃傾偼敪払偟偰曋棙偵側傝傑偟偨偑丄巊偄曽偵屗榝偭偰偟傑偆働乕僗傕懡偄偺偱偼側偄偱偟傚偆偐丅
Basic側懡曄検夝愅偲偟偰偼丄夞婣暘愅丄庡惉暘暘愅丄場巕暘愅丄偦偟偰敾暿暘愅側偳偑桳柤偱偡丅尰戙偵偍偄偰偼丄偙傟傜偺庤朄偺墳梡宍傗怴偨側傾儖僑儕僘儉傪摫擖偟偨懡庬懡條側庤朄偑峫埬偝傟偰偍傝傑偡丅 偙偙偱儅乕働僥傿儞僌挷嵏偱偟偽偟偽妶梡偝傟傞懡曄検夝愅偺偄偔偮偐偺庤朄傪偛徯夘抳偟傑偡丅
1. 僐儗僗億儞僨儞僗暘愅
僐儗僗億儞僨儞僗暘愅偼2偮偺僇僥僑儕僇儖曄悢偺憡屳娭學傪夝愅偡傞偙偲偑庡栚揑偱丄椺偊偽乽僽儔儞僪 x 僄僋僀僥傿乿側偳偺儅僢僺儞僌側偳偵傛偔巊傢傟傑偡丅偙偺庤朄偼僼儔儞僗偐傜抂傪敪偟丄擔杮偱偼乽懳墳暘愅乿偲屇偽傟偰偍傝傑偡丅 堦曽丄擔杮偵偍偄偰傕僇僥僑儕僇儖曄悢偺暘愅庤朄偼乽椦偺悢検壔棟榑乿偲偄偆撈帺偺恑壔傪悑偘丄摿偵乽悢検壔棟榑III椶乿偼悢棟揑偵僐儗僗億儞僨儞僗暘愅偲摨媊偱偁傞偙偲偑抦傜傟偰偄傑偡丅
暘愅帠椺
亂柦戣亃 庡梫昐壿揦乮壖憐乯偑偳偺傛偆側僀儊乕僕偱懆偊傜傟偰偄傞偐暘愅偡傞
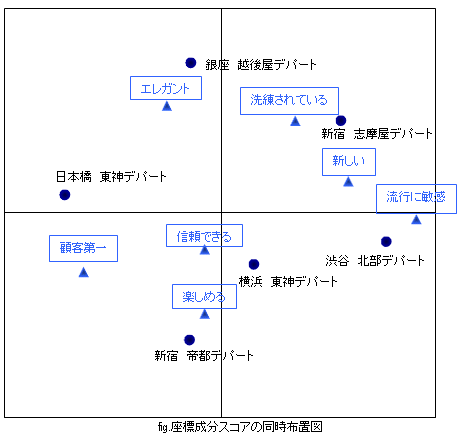
僐儗僗億儞僨儞僗暘愅偼埲壓偺傛偆側僋儘僗昞傪尦偵暘愅傪偐偗傑偡丅廬偭偰丄挷嵏偺帪偵揦曑僀儊乕僕偵娭偡傞幙栤傪愝偗偰偍偒傑偡丅
僐儗僗億儞僨儞僗暘愅偼僋儘僗昞偺峴楍斾棪偺斀墳僷僞儞偐傜娭學惈傪夝愅偟傑偡丅偙偺斀墳僷僞儞偼"僾儘僼傿儖"偲屇偽傟偰偍傝傑偡丅偙偙偱峴丄楍崌寁偺斀墳僷僞儞傪廳傒偲偡傞怴偨側峴楍傪嶌傝丄偲偁傞棟榑揑庤朄偵傛傝忣曬傪弅栺乮慄宍戙悢妛偵婎偯偔摿堎抣暘夝傪棙梡乯偟偨嵗昗惉暘僗僐傾偲偄偆傕偺傪嶼弌偟傑偡丅偙偺惉暘僗僐傾傪摨帪晍抲偡傞偙偲偵傛傝娭學惈傪峫嶡偟傑偡丅 僐儗僗億儞僨儞僗暘愅偼忣曬傪弅栺偟丄慡懱偺條巕傪挱傔傞偲偄偆揰偱庡惉暘暘愅偲旕忢偵傛偔帡偰偄傑偡丅僨乕僞偺嶲徠尦丄惗惉偺曽朄偑堎側傝丄庡惉暘暘愅偼曄悢偺暘嶶嫟暘嶶峴楍傗憡娭峴楍傪暘愅偺弌敪揰偲偟傑偡偑丄僐儗僗億儞僨儞僗暘愅偼曄悢偺昿搙僨乕僞傪弌敪揰偲偟傑偡丅
亂暘愅寢壥亃
峴楍曄悢偺嵗昗惉暘僗僐傾傪媮傔偨偲偙傠丄埲壓偺傛偆側2師尦暯柺偵晍抲偝傟偨偲偟傑偡丅偙偺嵗昗惉暘僗僐傾偼峴楍斾棪斀墳僷僞儞傪尦偵嶼弌偟偰偄傞偺偱愨懳揑側抣偺堄枴偼帩偪傑偣傫丅憡懳揑側嫍棧偑娭學惈傪昞偟偰偍傝傑偡丅僐儗僗億儞僨儞僗暘愅偼庡惉暘暘愅側偳偺傛偆偵幉偵懳偡傞夝庍偼捠忢峴偄傑偣傫丅
偙偺帠椺偵傛傞偲丄奺僨僷乕僩揦曑偼偍偍傓偹僀儊乕僕摿挿偺偲偙傠偵嶶傜偽偭偰晍抲偝傟偰偍傝丄偦傟偧傟偺屄惈偑巉偊傑偡丅椺偊偽丄嬧嵗丂墇屻壆僨僷乕僩偼崅媺側僀儊乕僕丄怴廻丂掗搒僨僷乕僩偼攦偄暔偑妝偟傔傞偲偄偭偨徚旓幰偵偲偭偰傛傝恎嬤側懚嵼偱偁傞偙偲偑帵嵈偝傟偰偄傑偡丅傑偨丄廰扟丂杒晹僨僷乕僩偼棳峴偵晀姶偱丄忢偵怴偟偄傕偺傪捛偄媮傔偰偄傞巔惃偱偁傞偙偲偑帵嵈偝傟偰偄傑偡丅偙偺寢壥偐傜偼僨僷乕僩偺僀儊乕僕偼揦曑庬暿偺傒側傜偢丄抧堟惈乮搚抧暱乯偲偄偆梫場傕娭學偟偰偄傞偲撉傒庢傞偙偲偑偱偒傞偺偱偼側偄偱偟傚偆偐丅
偙偺傛偆偵僐儗僗億儞僨儞僗暘愅偼丄曄悢娫偺暋嶨側娭學惈傪師尦弅栺偵傛傞扨弮壔傪帋傒丄傛傝傢偐傝傗偡偔慡懱傪峫嶡偡傞偙偲偑偱偒傑偡丅
2. 僋儔僗僞乕暘愅
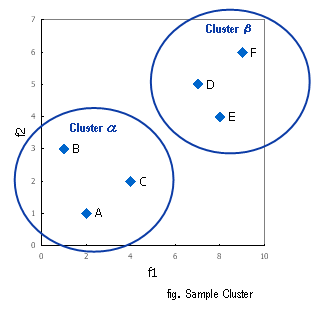
僋儔僗僞乕暘愅偲偼丄帡偨傕偺摨巑傪摨偠拠娫(Sample Cluster)偲偟偰妵傞偙偲傪庡栚揑偲偟偰偄傑偡丅偦偺"妵傝曽"偼揔摉偵妵傞偺偱偼側偔丄條乆側棟榑傪崻嫆偲偟偰崌棟揑偵張棟偟傛偆偲偄偆峫偊曽偱偡丅妵傜傟偨夠乮廤抍乯偺偙偲傪僋儔僗僞乕偲尵偄傑偡丅僋儔僗僞乕暘愅偱偼奺乆偺僋儔僗僞乕偵偮偄偰偺摿惈傪峫嶡偟丄懠偺暘愅偲慻傒崌傢偣傞偙偲偵傛偭偰僞乕僎僢僩丒僙僌儊儞僥乕僔儑儞側偳偱丄偦偺埿椡傪敪婗偟傑偡丅
屄乆偺僨乕僞偐傜"壗傪傕偭偰拠娫偲偡傞偐"偺掕媊丄娤揰偵偼條乆側峫偊曽偑偁傝傑偡丅椺偊偽丄"屳偄偺嫍棧偑嬤偄"佀"摨偠拠娫(Cluster)"偲懆偊傞偙偲偑偱偒傑偡丅偙偙偱偺"嫍棧"偺奣擮傕偄傠偄傠峫偊傜傟傑偡丅嫍棧偺掕媊偼僨乕僞傪n師尦嬻娫忋偵晍抲偟偨偲偒偺偄傢備傞尒偨栚忋偺嫍棧乮儐乕僋儕僢僪嫍棧乯傪棙梡偡傞応崌偐傜丄妋棪揑側峫偊曽乮屳偄偵弌尰妋棪偑崅偄帠徾偼嫍棧偑嬤偄偲掕媊偡傞乯傪摫擖偟偨儅僴儔僲價僗偺斈嫍棧側偳偱婯掕偡傞曽朄偑偁傝傑偡丅廬偭偰丄堦岥偵僋儔僗僞乕暘愅偲尵偭偰傕偙傟傜偺僐儞價僱乕僔儑儞偵傛傝Output傕偄傠偄傠偲曄梕偟摼傑偡丅
暘愅庤朄
僋儔僗僞乕暘愅偺庤朄偼戝偒偔2偮偵暘椶偝傟傑偡丅1偮偼暘椶偦偺傕偺偵奒憌峔憿傪帩偮亂奒憌揑庤朄亃丄傕偆1偮偼亂旕奒憌揑庤朄亃偵暘偗傜傟傑偡丅戙昞揑側傕偺傪偄偔偮偐埲壓偵偛徯夘抳偟傑偡丅
1)奒憌揑庤朄乧扨楢寢朄丄僂僅乕僪朄丄廳怱朄丄..etc..
2)旕奒憌揑庤朄乧k-means丄愽嵼崿崌儌僨儖丄..etc..
奒憌揑庤朄
屄乆偺僨乕僞偐傜忋埵奣擮偺僋儔僗僞乕偲偟偰廤栺偟偰偄偒傑偡丅 丂丂丂
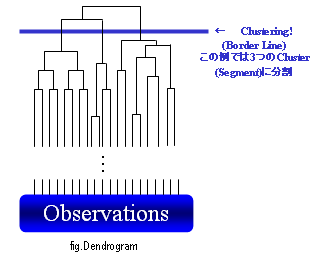
僨儞僪儘僌儔儉乮庽忬恾乯偲偄偆恾偱偦偺忬嫷偑昞尰偝傟傑偡丅
k-means
旕奒憌揑庤朄偺戙昞揑側庤朄偱丄僋儔僗僞乕暘愅偱偼昿斏偵棙梡偝傟傑偡丅旕奒憌揑庤朄偲偼婎弨偲傕尵偆傋偔"昡壙娭悢"傪婯掕偟偰嵟揔側僋儔僗僞儕儞僌傪峴偆庤朄偱偡丅k-means偼屄懱偲偦偺婣懏偡傞奺僋儔僗僞乕偺拞怱偲偺嫍棧偺暯曽榓偑嵟彫偲側傞傛偆側婎弨偱 扵嶕揑偵僋儔僗僞儕儞僌傪帋傒傑偡丅嬶懱揑側僋儔僗僞儕儞僌曽朄偼屄懱偺拞偐傜k屄偺弶婜抣傪掕傔偰丄偦傟埲奜偺屄懱偲偺嫍棧傪應傝傑偡丅嫍棧偑嬤偄傕偺摨巑傪摨堦僋儔僗僞乕偲偟偰妵傝丄怴偨偵僋儔僗僞乕偺拞怱傪媮傔傑偡丅偙偺嶌嬈傪嵟廔揑偵k屄偺僋儔僗僞乕偵廂懇偡傞傑偱偔傝曉偟傑偡丅
k-means朄偺寢壥偼弶婜抣偺愝掕偵埶懚偟傑偡丅摼傜傟偨寢壥偼嬊強嵟揔夝偱偁傝丄昡壙娭悢偺堦斒壔嵟彫抣夝偺嶼弌偼傾儖僑儕僘儉忋嬌傔偰崲擄偱偡丅捠忢偼弶婜抣傪偄偔偮偐曄壔偝偣丄昡壙娭悢偑嵟彫偺傕偺傪暘愅梡偲偟偰嵦梡偟傑偡丅堦斒偵暔帠偺暘椶偵偼條乆側娤揰偐傜偺曽朄偑偁傝"偙傟偑惓夝僋儔僗僞乕"偲偄偆傕偺偼懚嵼偟傑偣傫丅偱偡偺偱偦傟傪抁強偲懆偊偢丄傛傝尰幚偵懄偟偨廮擃側暘椶偑偱偒傞偲慜岦偒偵懆偊傞曽偑尗柧偲巚傢傟傑偡丅
愽嵼崿崌儌僨儖
愽嵼崿崌儌僨儖偲偼丄暘晍偺攚屻偵妋棪儌僨儖傪婯掕偟偰暘椶乮僋儔僗僞儕儞僌乯偡傞峫偊曽偱偡丅 屄乆偺僋儔僗僞乕偺僨乕僞敪惗婡峔偑妋棪暘晍偵廬偄撈棫帠徾偱偁傞偲壖掕偟偨偲偒丄僨乕僞x偺暘晍偼偦偺摨帪暘晍偵憡摉偟傑偡丅
椺偊偽丄埲壓偺嵍恾偼抝惈丗彈惈亖4:6偱峔惉偝傟偨乮壖憐乯曣廤抍偺恎挿偺妋棪暘晍傪昞偟偨傕偺偱偡丅抝惈偺暯嬒偼170cm丄彈惈偺暯嬒偼160cm偲壖掕偡傞偲丄彈惈偺峔惉斾棪偺曽偑懡偄暘丄庒姳嵍懁偺嶳偑崅偔側偭偰偍傝傑偡丅
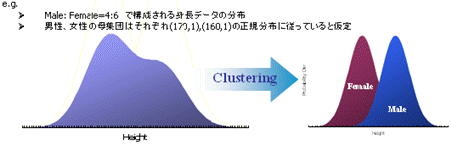
偙偺帠椺偱偼妋棪曄悢偑1曄悢乮恎挿乯偱丄暘暿偡傞幉傕婛抦乮惈暿乯側偺偱丄僋儔僗僞儕儞僌偼敾暿暘愅側偳傪梡偄偰梕堈偵峴偆偙偲偑偱偒傑偡丅偟偐偟丄幚嵺偺応柺偱偼堦斒偵曄悢偼傕偭偲偨偔偝傫偁傝丄暘暿偡傞幉傕側偵傪婎弨偲偟偨傜椙偄偐傢偐傜側偄応崌偑彮側偔偁傝傑偣傫丅愽嵼崿崌儌僨儖偱偼偙偺暘暿幉傪愽嵼揑側曄悢偲偟偰僋儔僗僞儕儞僌偟傑偡丅峏偵丄僋儔僗僞乕傪偄偔偮偵暘偗傟偽椙偄偐尒摉偑偮偐側偄偙偲傕懡偄偲巚偄傑偡丅愽嵼崿崌儌僨儖偼妋棪儌僨儖桼棃偺偨傔AIC,BIC偲偄偭偨忣曬検婯弨傪嶲徠偡傞偙偲偑偱偒傑偡丅偙傟偵傛傝儌僨儖慡懱偺椙偟埆偟偑敾抐偱偒丄嵟揔側僋儔僗僞乕悢偑偄偔偮偱偁傞偐傪棟榑揑偵帵嵈偟偰偔傟傑偡丅 傑偨丄愽嵼崿崌儌僨儖偼SEM偲偺恊榓惈偑崅偔丄SEM偺壓埵儌僨儖偲偟偰懆偊傞峫偊曽傕敪払偟偰偒偰偍傝傑偡丅
Fuzzy c-means
峫偊曽偼k-means偲傛偔帡偰偄傑偡丅k-means朄偱偼奺乆偺屄懱偼"Cluster 兛偵懏偡傞"側偳堦堄偵掕傑傝傑偡丅偦傟偵懳偟偰Fuzzy c-means偼昡壙娭悢偵0偐傜1偺楢懕抣傪庢傞"婣懏搙"偲偄偆奣擮傪抲偄偨儌僨儖偱僋儔僗僞儕儞僌偝傟傑偡丅偮傑傝丄"Cluster 兛偵婣懏搙0.7丄Cluster 兝偵偼婣懏搙0.3 偱懏偡傞丅"偲尵偆傛偆偵丄濨枂偝傪嫋梕偡傞僋儔僗僞乕暘愅偱偡丅
暘愅帠椺
亂柦戣亃 偲偁傞僄僗僥傿僢僋僒儘儞偺揦曑偱屭媞枮懌搙傪岠棪揑偵岦忋偝偣傞偨傔丄崱屻偳偺傛偆側恖偨偪偵偳傫側傾僋僔儑儞僾儔儞傪嶔掕偡傟偽椙偄偐専摙偡傞丅
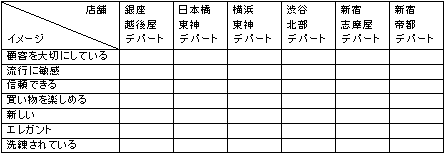
挷嵏偺崁栚偲偟偰偼懳徾幰偺摿惈忣曬乮惈丒擭戙側偳乯傪偼偠傔丄揦曑傊偺棃揦忬嫷丄杮恖偺壙抣娤丄廗姷側偳丄條乆忣曬傪廂廤偟丄僋儔僗僞乕暘愅傪巤偟傑偟偨丅3偮偺僋儔僗僞乕偵暘椶偱偒丄偦傟偧傟偺屭媞僞僀僾暿偵傾僋僔儑儞僾儔儞傪嶔掕偟傑偟偨丅偙偺帠椺偱偼Cluster兝偺"愽嵼屭媞丂柆偁傝僋儔僗僞乕乭偲柦柤偟偨廤抍偑峔惉斾棪傕崅偔億僥儞僔儍儖傕崅偄偲梊憐偝傟丄枮懌搙傪岠棪揑偵忋偘傞偨傔偵偼僾儔僀僆儕僥傿偺崅偄屭媞僙僌儊儞僩偱偁傞偲尵偊傞偺偱偼側偄偱偟傚偆偐丅

儁乕僕忋傊